Massive X(Twitter) unfollow
Massive X(Twitter) unfollow
How it looks
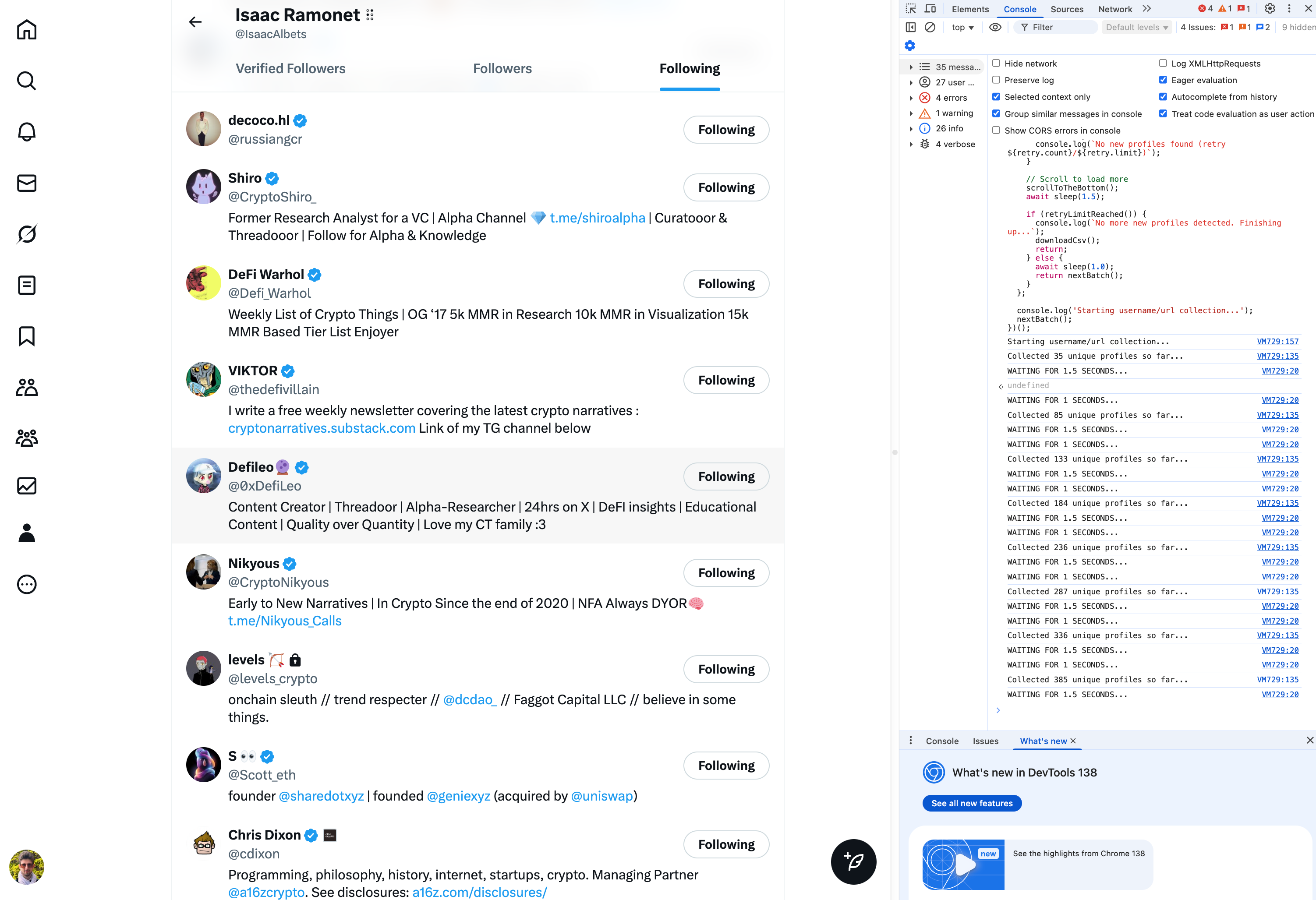
Running
Completed running with the csv downloaded automatically
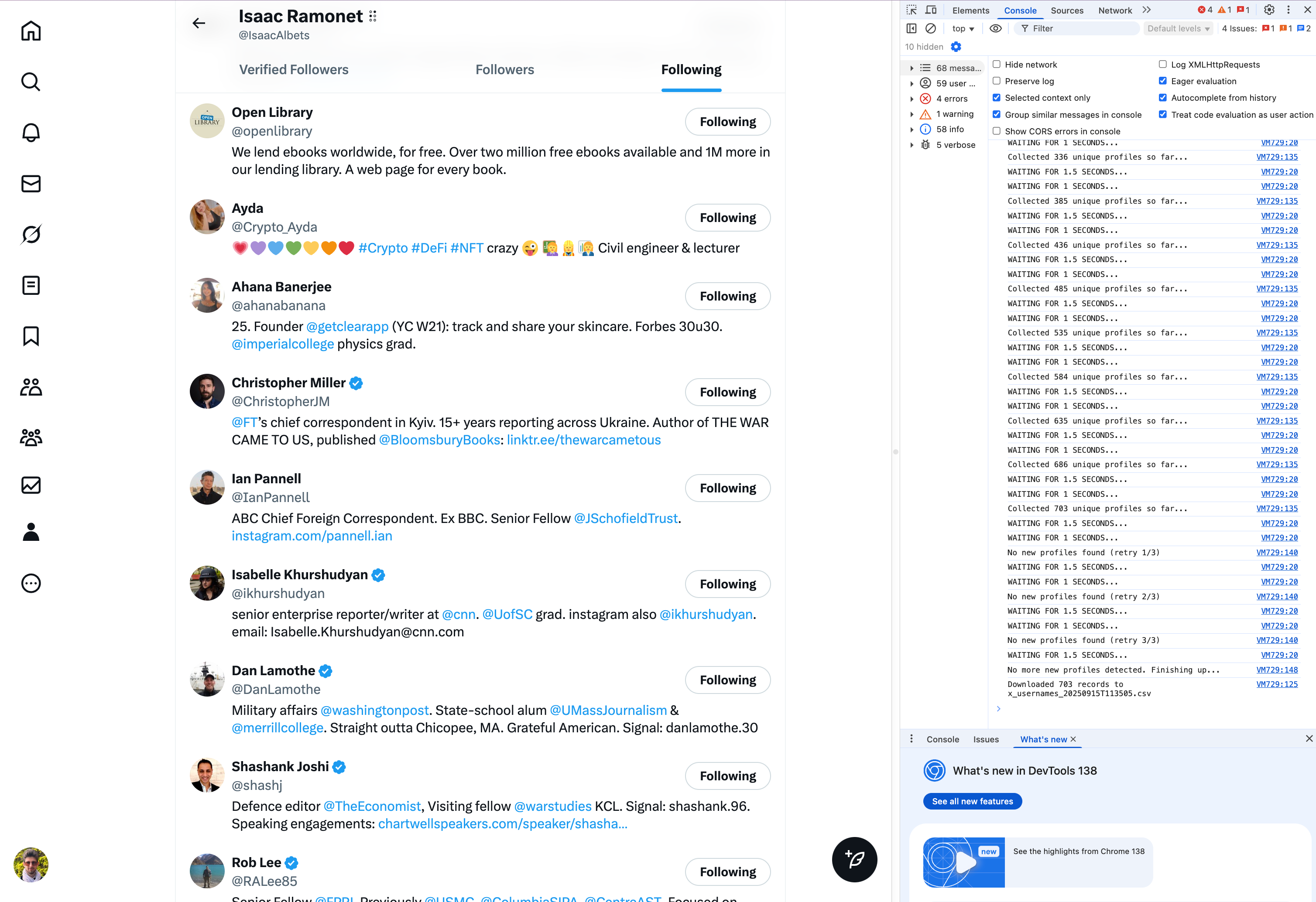
And the results.

If you want to do the same, follow the instructions below.
Instructions
Go to X.com and navigate to this url: https://x.com/YOUR_HANDLE/following
Open developer tools and click on console
Copy paste this script. It will unfollow everyone and save all handles in a spreadsheet that it will automatically download. (Feel free to inspect the script or ask ChatGPT to explain it to you if you have doubts).
- Keep the page open while it is running.
- You might need to re-run it as it might hit the platform limits and stop loading.
Share your results If this has worked for you please share tagging @IsaacAlbets
NOTE: if you want to download ALL people you follow separately, check this script
// Modified and adapted script, based on: https://github.com/nirholas/UnfollowX
(() => {
const $followButtons = '[data-testid$="-unfollow"]';
const $confirmButton = '[data-testid="confirmationSheetConfirm"]';
const $userCell = '[data-testid="UserCell"]';
// uncomment if you want to capture the bio for each profile into the csv
//const $bio = '[data-testid="UserDescription"]';
const retry = { count: 0, limit: 3 };
const seen = new Set(); // handles (no @)
const rows = []; // { username: '@handle', url: 'https://x.com/handle', bio: '...' }
const scrollToTheBottom = () =>
window.scrollTo(0, document.body.scrollHeight);
const retryLimitReached = () => retry.count === retry.limit;
const addNewRetry = () => retry.count++;
const resetRetry = () => (retry.count = 0);
const sleep = ({ seconds }) =>
new Promise((proceed) => setTimeout(proceed, seconds * 1000));
const jitter = (minMs, maxMs) =>
Math.floor(Math.random() * (maxMs - minMs + 1)) + minMs;
const asAbsoluteUrl = (path) => {
try {
return new URL(path, location.origin).toString();
} catch {
return `${location.origin}${path}`;
}
};
const textClean = (s) => (s || "").replace(/\s+/g, " ").trim();
const findProfileAnchor = (rootEl) => {
if (!rootEl) return null;
const anchors = rootEl.querySelectorAll('a[role="link"][href^="/"]');
const profileRe = /^\/([A-Za-z0-9_]{1,15})\/?$/; // /handle only
for (const a of anchors) {
const href = a.getAttribute("href") || "";
if (profileRe.test(href)) return a;
}
return null;
};
const extractBio = (cell, handle) => {
// 1) Primary: explicit UserDescription node
const primary = cell?.querySelector($bio);
if (primary) return textClean(primary.textContent);
// 2) Heuristic fallback: take the longest textual chunk within the cell,
// filtering obvious non-bio bits (handle, badges, "Follows you", etc.)
const h = (handle || "").replace(/^@/, "");
const bits = Array.from(cell?.querySelectorAll('[dir="auto"]') || [])
.map((el) => textClean(el.textContent))
.filter(Boolean)
.filter((t) => !t.startsWith("@"))
.filter((t) => !t.includes("Follows you"))
.filter((t) => !t.includes("Followed by"))
.filter((t) => !t.includes("Follows"))
.filter((t) => !t.includes("Verified"))
.filter((t) => t.toLowerCase() !== h.toLowerCase());
// pick the longest as a decent proxy for bio
return textClean(bits.sort((a, b) => b.length - a.length)[0] || "");
};
const recordUser = (handle, bio) => {
const clean = handle.replace(/^@/, "");
if (!clean || seen.has(clean)) return false;
seen.add(clean);
const record = {
username: `@${clean}`,
url: asAbsoluteUrl(`/${clean}`),
};
if (bio) {
record.bio = extractBio(bio);
}
rows.push(record);
return true;
};
const downloadCsv = () => {
const header = "username,url,bio";
const lines = rows.map(({ username, url, bio }) => {
const esc = (v) =>
`"${String(v ?? "")
.replace(/\r?\n/g, " ")
.replace(/"/g, '""')}"`;
return [esc(username), esc(url), esc(bio)].join(",");
});
const csv = [header, ...lines].join("\n");
const stamp = new Date()
.toISOString()
.replace(/[-:]/g, "")
.replace(/\..+/, "");
const filename = `x_usernames_${stamp}.csv`;
const blob = new Blob([csv], { type: "text/csv;charset=utf-8;" });
const dlUrl = URL.createObjectURL(blob);
const a = document.createElement("a");
a.href = dlUrl;
a.download = filename;
document.body.appendChild(a);
a.click();
a.remove();
URL.revokeObjectURL(dlUrl);
console.log(`Downloaded ${rows.length} records to ${filename}`);
};
// IMPORTANT: sequential (not Promise.all) so confirm dialogs don’t collide
const unfollowAll = async (followButtons) => {
console.log(`UNFOLLOWING ${followButtons.length} USERS...`);
for (const followButton of followButtons) {
if (!followButton) continue;
// Grab user info before state changes
const cell =
followButton.closest($userCell) || followButton.parentElement;
const a = findProfileAnchor(cell || followButton);
if (a) {
const m = a.getAttribute("href")?.match(/^\/([A-Za-z0-9_]{1,15})\/?$/);
if (m) {
const handle = m[1];
// uncomment if you want to capture the bio for each profile into the csv
// const bio = extractBio(cell, handle);
// recordUser(handle, bio)
recordUser(handle); // comment out if you want to keep the bio for each profile
}
}
// Click unfollow then confirm (if present)
followButton.click();
await sleep({ seconds: 0.2 });
const confirmButton = document.querySelector($confirmButton);
if (confirmButton) confirmButton.click();
// Small randomized delay to avoid hammering
await new Promise((r) => setTimeout(r, jitter(500, 1000)));
}
};
const nextBatch = async () => {
scrollToTheBottom();
await sleep({ seconds: 1 });
const followButtons = Array.from(document.querySelectorAll($followButtons));
const followButtonsWereFound = followButtons.length > 0;
if (followButtonsWereFound) {
await unfollowAll(followButtons);
resetRetry();
await sleep({ seconds: 2 });
return nextBatch();
} else {
addNewRetry();
}
if (retryLimitReached()) {
console.log(`NO ACCOUNTS FOUND, I THINK WE'RE DONE`);
if (rows.length) downloadCsv();
console.log(`RELOAD PAGE AND RE-RUN SCRIPT IF ANY WERE MISSED`);
} else {
await sleep({ seconds: 2 });
return nextBatch();
}
};
console.log("Starting blended collect (with bio) + unfollow run…");
nextBatch();
})();